



April 21, 2023
Data Fabric Deep Dive Part 1: The Relationship Between the Data Fabric and Data Mesh
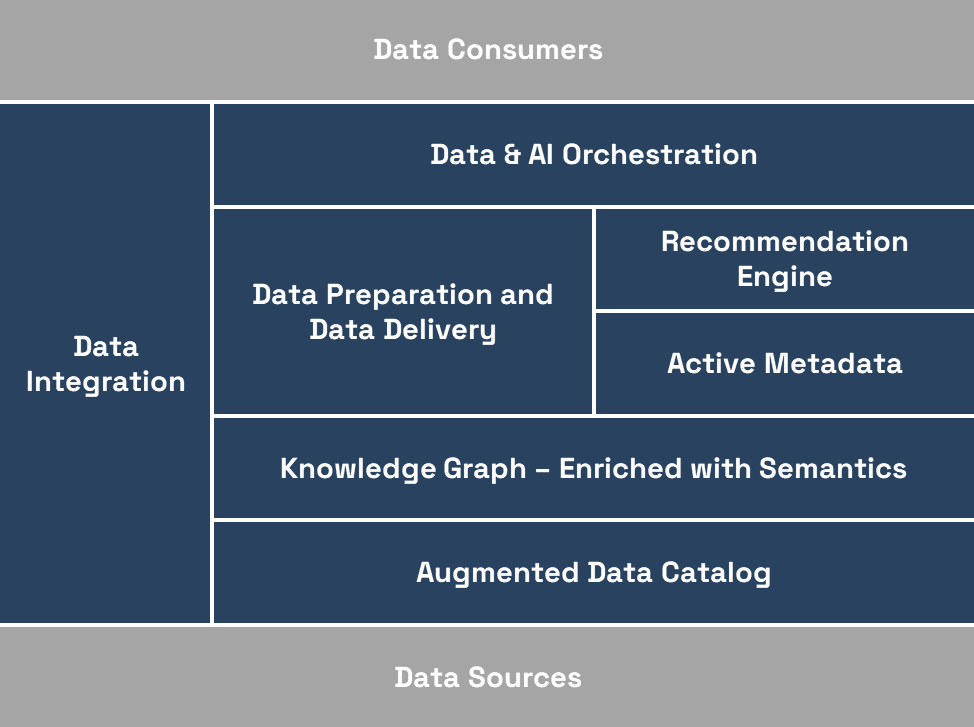
Two of the hottest topics in the last two years in the data management / analytics space are without a doubt the Data Fabric and the Data...
Continue Reading »